[LangChain]Classification
1 概述
标签是指使用各类分类对文档进行标注,包括但不限于:
- 情感分析:识别文档中的主观信息,判断作者的态度是积极、消极还是中立。
- 语言类型:确定文档所使用的语言,如英语、汉语等。
- 文体(正式、非正式等):根据文档的语言风格进行分类,适用于不同场合和读者群体的需求。
- 覆盖的主题:标识文档讨论的主要话题或领域,有助于快速了解文档内容的核心。
- 政治倾向:评估文档内容是否表现出特定的政治立场或观点。
这些标签能够帮助我们更好地理解和管理大量文本数据,提高信息检索的效率,并支持更精确的内容推荐和分析。例如,在构建一个新闻聚合平台时,通过自动化的标签技术,可以实现对新闻文章的智能分类与个性化推送,从而增强用户体验。
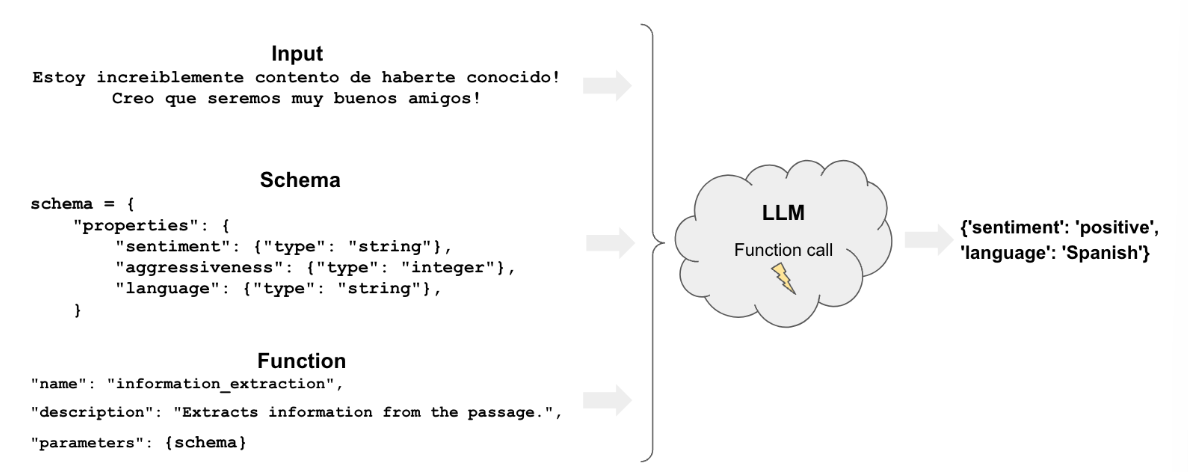
标签技术主要包括以下几个组成部分:
function:类似于信息抽取,标签过程使用特定的功能函数来指定模型应如何对文档进行分类。这些函数指导模型识别并应用适当的标签到文本数据上。
schema:定义了我们希望如何对文档进行标注的结构和规则。模式详细说明了使用的标签类型、标签之间的关系以及它们在不同上下文中的应用方式。
示例
首先,定义一个Pydantic模型,包含几个属性及其预期类型:
1 | |
使用ChatPromptTemplate构建提示模板,以提取所需信息:
1 | |
最后,结合语言模型与定义的Pydantic模型,以实现结构化的输出:
1 | |
1 | |
如果想要dict格式的输出,可以直接调用 .model_dump()
1 | |
2 Finer Control
精确的Schema定义使我们对模型输出具有更多的控制力。具体来说,可以通过以下方式来增强对每个属性的控制:
- 为每个属性定义可能的值。
- 提供描述以确保模型正确理解各个属性的意义。
- 指定必须返回的属性。
重新声明之前的Pydantic模型,并使用枚举(enum)来控制各属性的取值范围。
1 | |
其中 ... 用来表示该字段是必须的。
3 更多信息
可以参考 metadata tagger 从Document对象中提取metadata。和上述功能一致,只不过支持 Document对象.
[LangChain]Classification
https://erlsrnby04.github.io/2025/03/29/LangChain-Classification/