[MySql]Mysql
1 基础知识
1.1 数据库相关概念
数据库:存储数据的仓库,其中数据是有组织的存储起来的。
数据库管理系统:操纵和管理数据库的软件
SQL:操纵关系型数据库的编程语言。
1.2 MySQL数据库的安装
windows
直接去官网下载安装包,按照默认安装即可。
启动和停止
- windows+r 输入services.msc找到mysql80。
- 命令行输入
- net start mysql80
- net stop mysql80
客户端连接
- mysql提供的客户端命令行工具
- 系统自带的命令行连接
- 命令:
mysql [-h 127.0.0.1] [-P 3306] -u root -p - 这种方式需要配置环境变量
- 命令:
Linux
1.3 MySQL数据模型
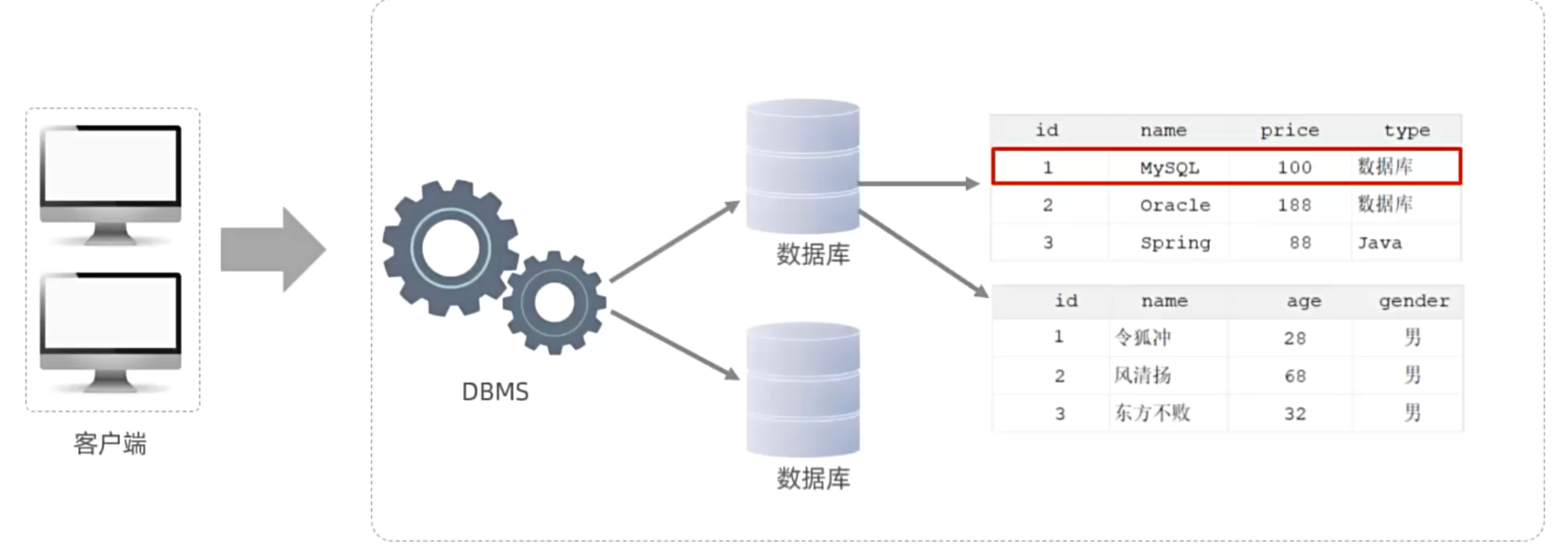
如图所示,我们的客户端通过SQL将要执行的操作发送给DBMS,然后由其帮助我们去操作、创建数据库。
关系型数据库:建立在关系模型基础上,由多张相互连接的二维表组成的数据库
2 SQL
2.1 SQL通用语法
- 可以单行或者多行书写,以分号结尾
- 可以使用空格/缩进增加可读性
- 不区分大小写,关键字建议用大写
- 注释
- 单行注释:
-- 注释内容/# 注释内容 - 多行注释:
/*注释内容*/
- 单行注释:
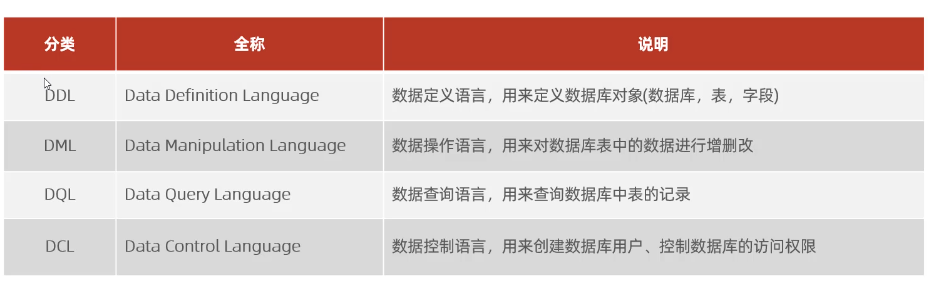
2.2 SQL分类
2.3 DDL
2.3.1 数据库操作
查询
- 查询所有数据库:
SHOW DATABASES; - 查询当前数据库:
SELECT DATABASE();
创建
1 | |
- if not exists:如果不存在则创建;存在不进行任何操作
- default charset:指定字符集
- collate:指定排序规则
删除
1 | |
- if exists:如果存在则删除
使用
1 | |
2.3.2 表操作
查询
- 查看当前数据库所有表
1 | |
必须先使用USE进入一个具体的数据库。
- 查询表结构
1 | |
- 查询指定表的建表语句
1 | |
创建
1 | |
例子
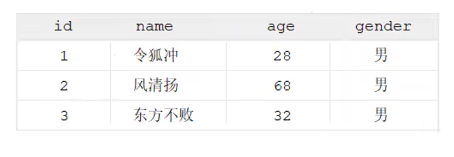
1 | |
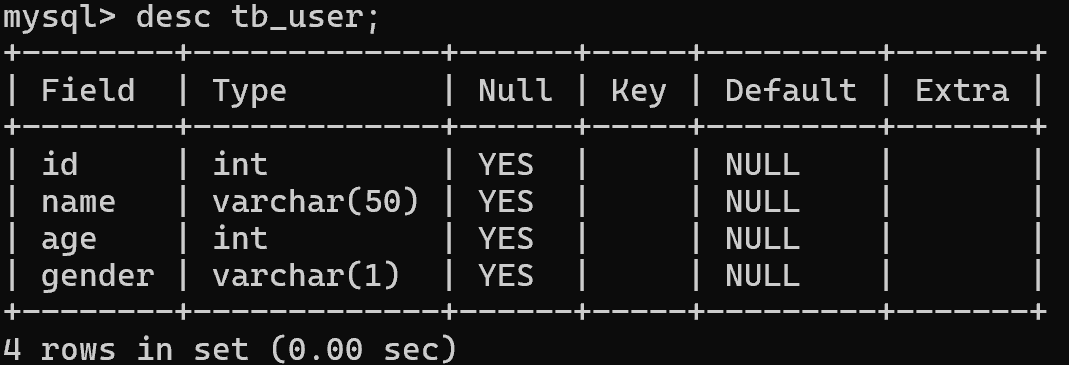
用decs命令来查看表结构
用show create table命令来查看建表语句
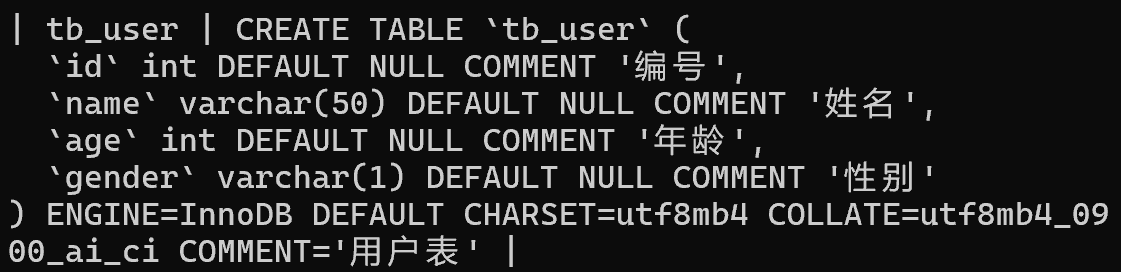
数据类型
主要分为三类
- 数值类型
- 字符串类型
- 日期时间类型
数值类型
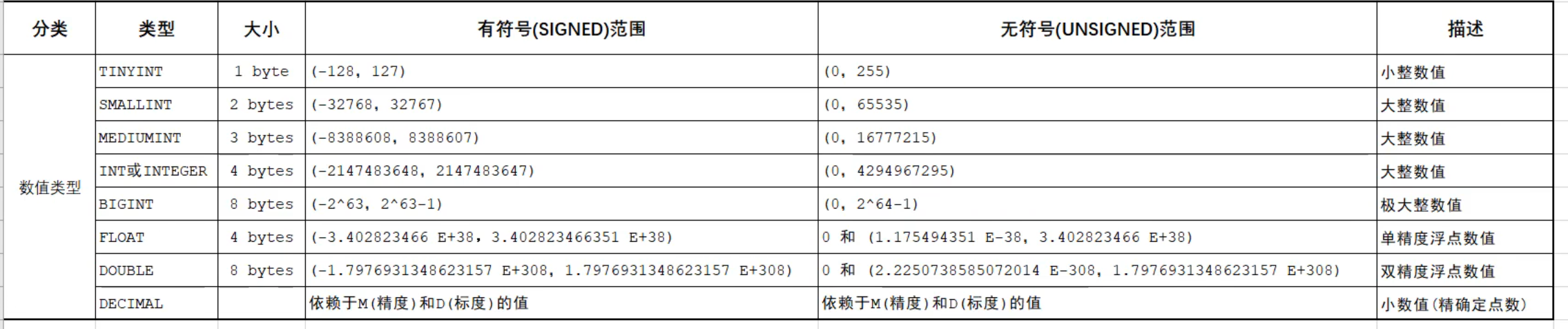
例子:
- age TINYINT UNSIGNED
- score double(4,1) # 4代表整体长度,1代表小数位数
字符串类型
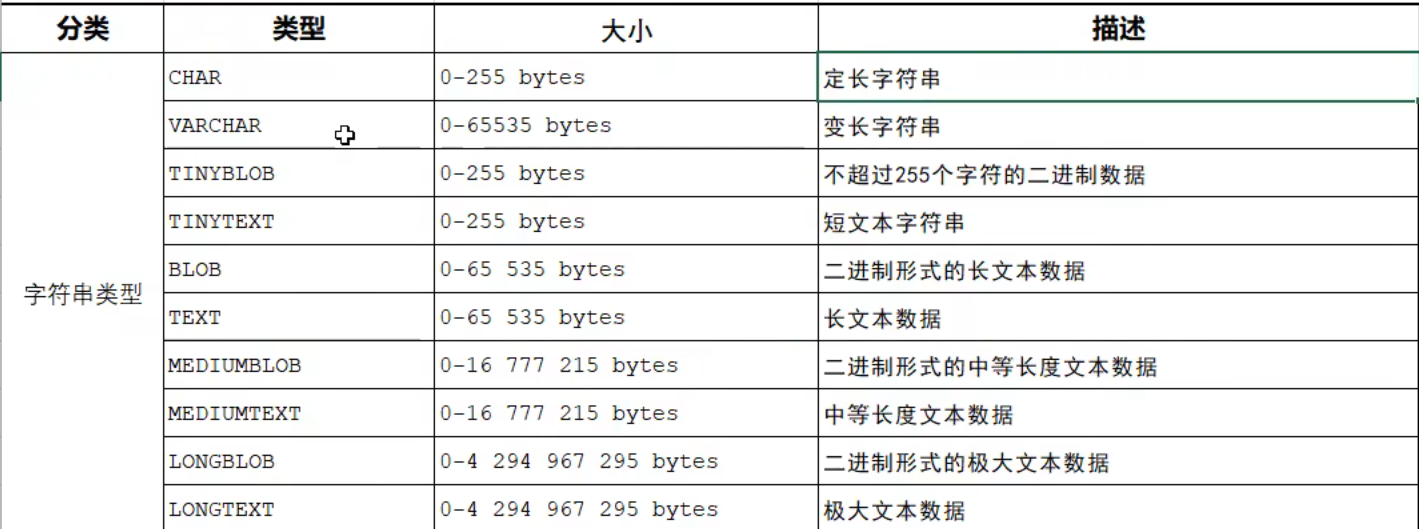
char和varchar都需要指明最大长度:
- 对于char(10):存储几个字符都占用10个空间(用空格补齐)
- 对于varchar(10):存储几个字符就占用几个字符的空间
char的性能高,varchar性能较差。
日期时间类型

修改表
- 添加字段
1 | |
修改字段
- 修改字段类型
1
ALTER TABLE 表名 MODIFY 字段名 新数据类型;- 修改字段名和字段类型
1
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型 [COMMENT 注释] [约束]删除字段
1
ALTER TABLE 表名 DROP 字段名;修改表名
1 | |
删除表
- 删除表
1 | |
- 删除指定表,并重新创建该表
1 | |
2.4 DML
对数据库中表的数据记录进行增删改操作。
- 添加数据(INSERT)
- 修改数据(UPDATE)
- 删除数据(DELETE)
2.4.1 添加数据
- 给指定字段添加数据
1 | |
- 给全部字段添加数据
1 | |
- 批量添加数据
1 | |
2.4.2 修改数据
1 | |
2.4.3 删除数据
1 | |
2.5 DQL
数据查询语言,用来查询数据库中表的记录。
关键字:SELECT
语法
1 | |
2.5.1 基本查询
- 查询多个字段
1 | |
- 设置别名
1 | |
- 去除重复记录
1 | |
2.5.2 条件查询
- 基本语法
1 | |
- 条件
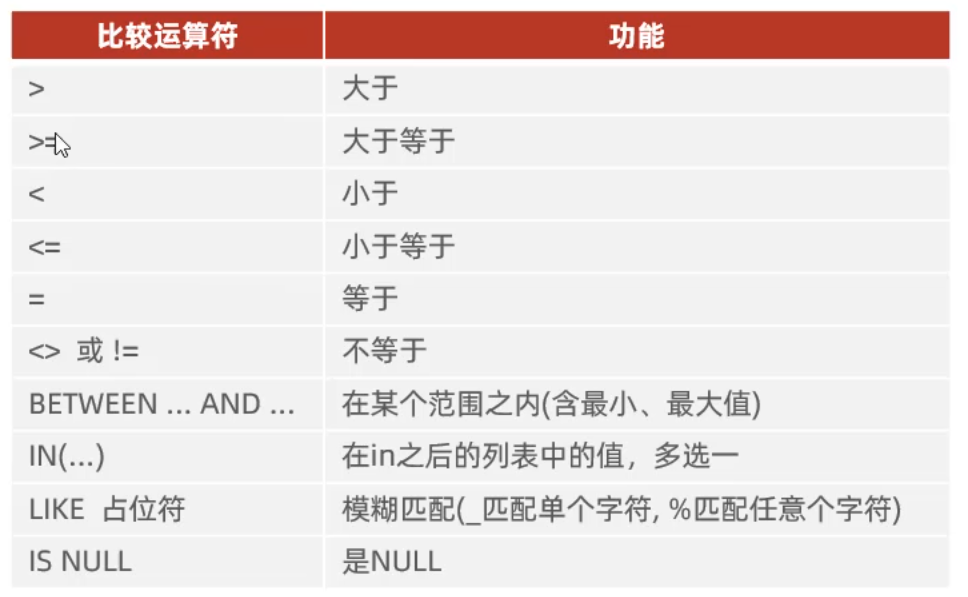
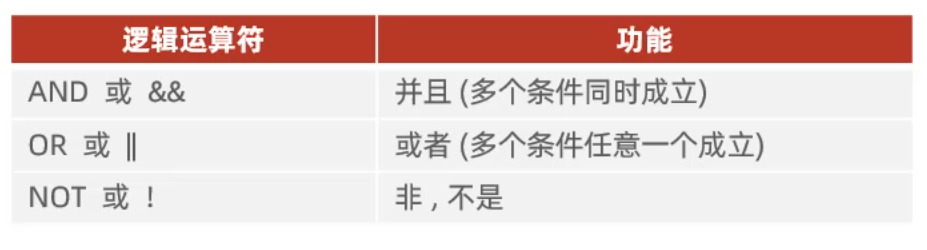
2.5.3 聚合函数
将一列数据作为一个整体,进行纵向计算。
常见聚合函数
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
语法
1 | |
注意
null值不参与计算。
2.5.4 分组查询
语法
1 | |
where与having区别
- 执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以。
注意
- 执行顺序:where > 聚合函数 > having
- 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
2.5.5 排序查询
语法
1 | |
排序方式
- ASC:升序(默认值)
- DESC:降序
2.5.6 分页查询
语法
1 | |
注意
- 起始索引从0开始,起始索引=(查询页码-1)* 每页记录数。
- 分页查询是数据库的方言,不同的数据库有不同的实现,mysql是LIMIT
- 如果查询的是第一页数据,起始索引可以省略,直接简写为limit 10.
2.5.7 DQL执行顺序

2.6 DCL
用来管理数据库用户、控制数据库的访问权限。
2.6.1 管理用户
- 查询用户
1 | |
- 创建用户
1 | |
- 修改用户密码
1 | |
- 删除用户
1 | |
2.6.2 权限控制
常用权限
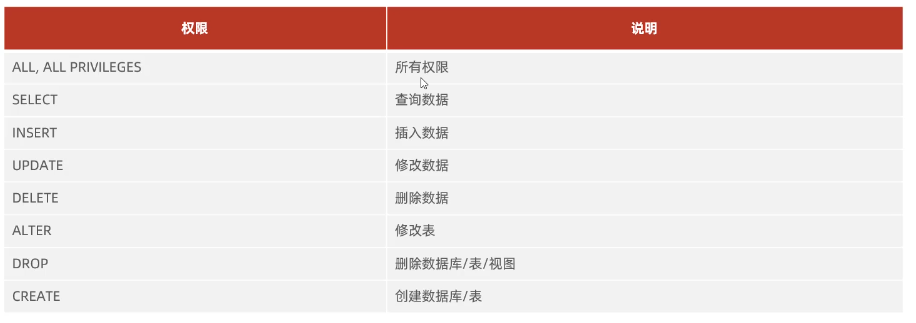
- 查询权限
1 | |
- 授予权限
1 | |
- 撤销权限
1 | |
3 函数
3.1 字符串函数
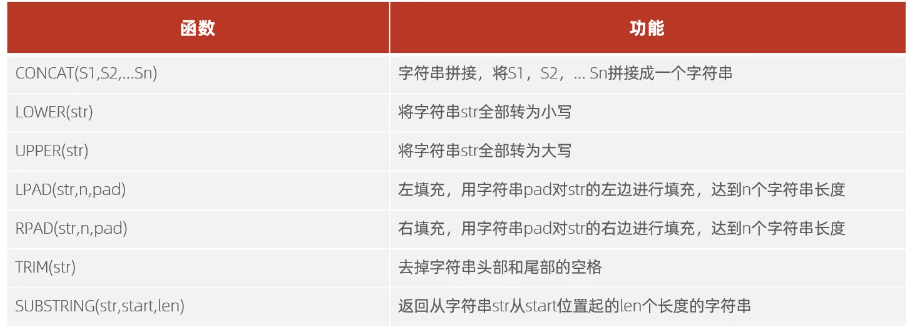
3.2 数值函数
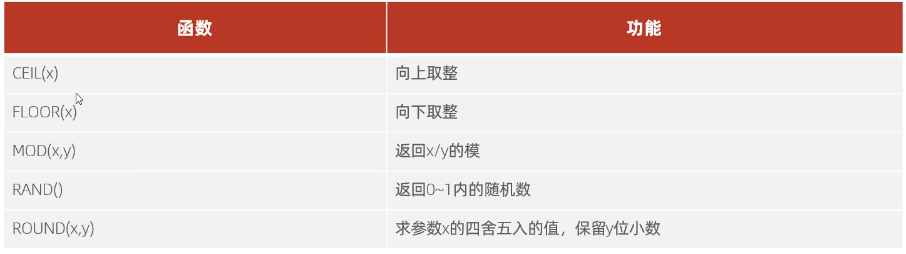
3.3 日期函数
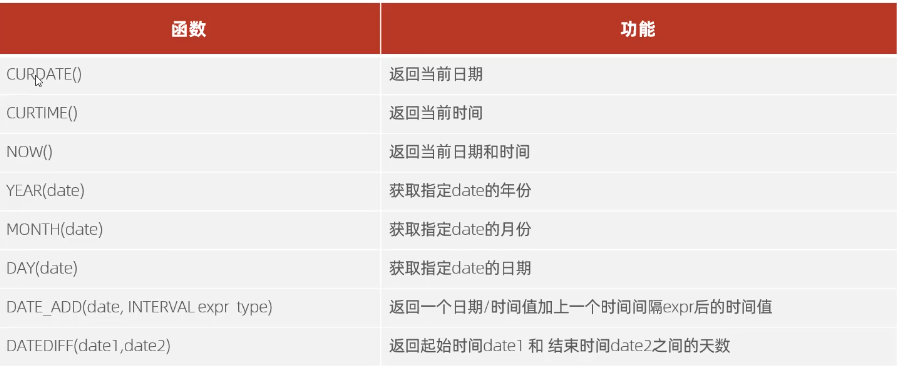
3.4 流程函数
4 约束
概念:作用于表中字段上的规则,用于限制存储在表中的数据
目的:保证数据库中数据的正确、有效和完整
分类

案例
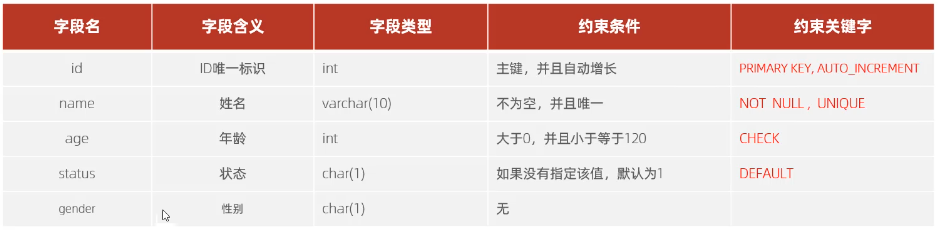
1 | |
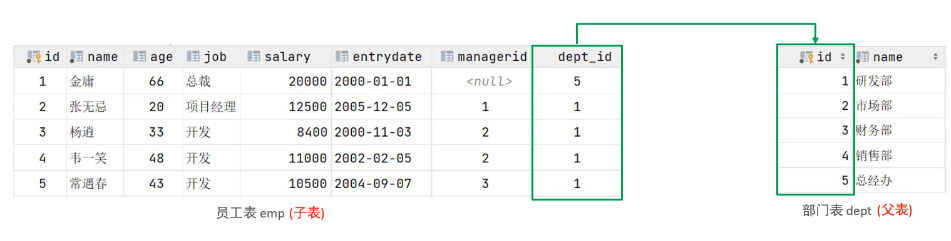
4.1 外键约束
概念:用来让两张表的数据之间建立连接,从而保证数据的一致性和完整性。
语法
- 添加外键
1 | |
- 删除外键
1 | |
删除/更新行为

1 | |
5 多表查询
5.1 多表关系
5.1.1 一对多
例如部门与员工的关系,一个部门对应多个员工,一个员工对应一个部门。
实现:在多的一方建立外键,指向一的一方的主键。
5.1.2 多对多
例如学生和课程之间的关系,一个学生可以选修多门课程,一门课程也可以被多个学生选修。
实现:建立一张中间表,至少包含两个外键,分别关联双方的主键。
5.1.3 一对一
例如用户与用户详情之间的关系。多用于单表拆分,将一张表的基础字段放在一张表中,其他详情放在另外一张表中,以提升操作效率。
实现:在任意一方加入外键,关联另一方的主键,并且设置外键为唯一的(unique)
5.2 多表查询概述
概述:从多张表中查询数据
笛卡尔积:两个集合A和B的所有组合情况(多表查询时,需要消除无效的笛卡尔积)。
5.3 连接查询
5.3.1 内连接
查询A、B交集部分的数据。
语法
1 | |
5.3.2 外连接
左外连接
查询左表所有数据,以及两表交集部分的数据。
1 | |
右外连接
查询右表所有数据,以及两表交集部分的数据。
1 | |
5.3.3 自连接
当前表与自身的连接查询,自连接必须使用表别名。
1 | |
5.4 联合查询
关键字:union,union all
把多次查询的结果合并起来,形成一个新的查询结果。
1 | |
- UNION会对结果去重
- UNION ALL直接将两次查询的结果拼接到一起
- 多张表的列数必须保持一致,字段类型也需要保持一致
5.5 子查询
概念:在sql语句中嵌套select语句,成为嵌套查询,也叫子查询。
1 | |
5.5.1 标量子查询
子查询放回的结果是单个值。
常用的操作符:=,<>,>,<,>=,<=
案例
查询销售部的所有员工信息
1 | |
5.5.2 列子查询
子查询返回的结果是一列。
常用的操作符:IN, NOT IN, ANY, SOME, ALL

5.5.3 行子查询
子查询返回的结果是一行。
常用的操作符:=, <>, IN, NOT IN
案例
查询与张无忌工资以及直属领导相同的员工信息
1 | |
5.5.4 表子查询
子查询返回的结果是多行多列。
常用的操作:IN
主要是用到from之后,将临时结果作为表从中查询。
案例
查询与“鹿杖客”,“宋远桥”的职位和薪资相同的员工信息
1 | |
查询入职日期是’2006-01-01’之后的员工信息,及部门信息。
1 | |
5.6 多表查询案例
- 查询员工的姓名、年龄、职位、部门信息。
1 | |
- 查询年龄小于30的员工姓名、年龄、职位、部门信息。
1 | |
- 查询拥有员工的部门ID、部门名称。
1 | |
- 查询所有年龄大于40岁的员工,及其归属的部门名称;如果员工没有分配部门,也需要展示出来。
1 | |
- 查询所有员工的工资等级。
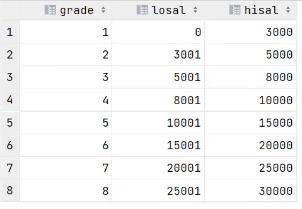
1 | |
- 查询研发部所有员工的信息及工资等级。
1 | |
- 查询研发部员工的平均工资。
1 | |
- 查询工资比灭绝高的员工信息。
1 | |
- 查询比平均薪资高的员工信息。
1 | |
- 查询低于本部门平均工资的员工信息。
1 | |
- 查询所有的部门信息,并统计部门的员工人数。
1 | |
6 事务
6.1 事务简介
事务是一组操作的集合,是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,要么同时成功,要么同时失败。
默认mysql的事务是自动提交的,当执行一条sql语句,mysql会立即隐式的提交事务。
6.2 事务操作
- 查看/设置事务提交方式
1 | |
- 提交事务
1 | |
- 回滚事务
1 | |
- 开启事务
1 | |
6.3 事务四大特性ACID
- 原子性(atuomicity):事务是不可分割的最小操作单元。
- 一致性(consistency):事务完成时,必须使所有的数据都保持一致状态
- 隔离性(isolation):保证事务在不受外部并发操作影响的独立环境下运行
- 持久性(durability):事务一旦提交或者回滚,对数据的改变就是永久的
6.4 并发事务问题

6.5 事务隔离级别
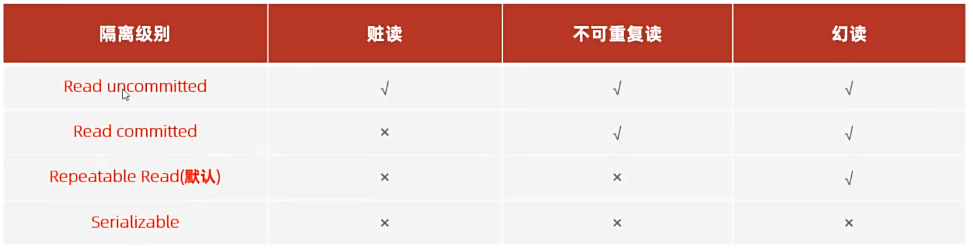
从上到下,隔离级别越来越高,性能越来越差。
- 查看事务隔离级别
1 | |
- 设置事务隔离级别
1 | |
SESSION|GLOBAL字段指明是设置当前会话的隔离级别还是全局的隔离级别。
7 存储引擎
7.1 mysql体系结构
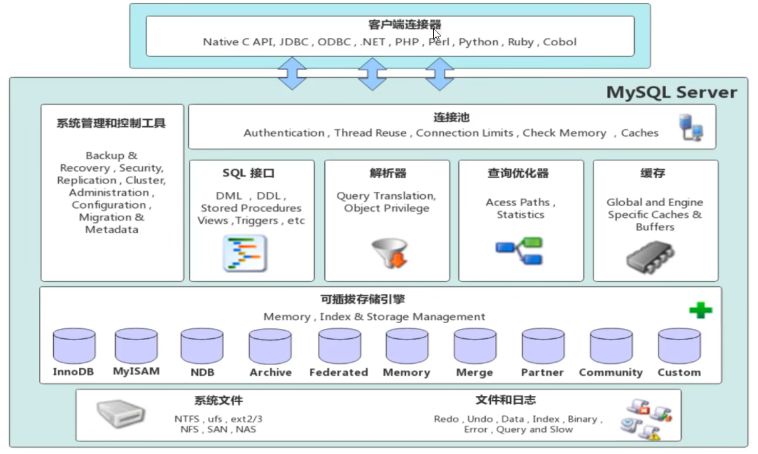
- 连接层:最上层是一些客户端和链接服务,主要完成一些类似于连接处理、授权认证、及相关的安全方案。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
- 服务层:第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化,部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如 过程、函数等。
- 引擎层:存储引擎真正的负责了MvSQL中数据的存储和提取,服务器通过API和存储引擎进行通信。不同的存储引擎具有不同的功能,这样我们可以根据自己的需要,来选取合适的存储引擎。
- 存储层:主要是将数据存储在文件系统之上,并完成与存储引擎的交互,
7.2 存储引擎简介
存储引擎是存储数据、建立索引、更新/查询数据等技术的实现方式。存储引擎是基于表的,而不是基于库的。
- 在创建表时,指定存储引擎
1 | |
- 查看当前数据库支持的存储引擎
1 | |
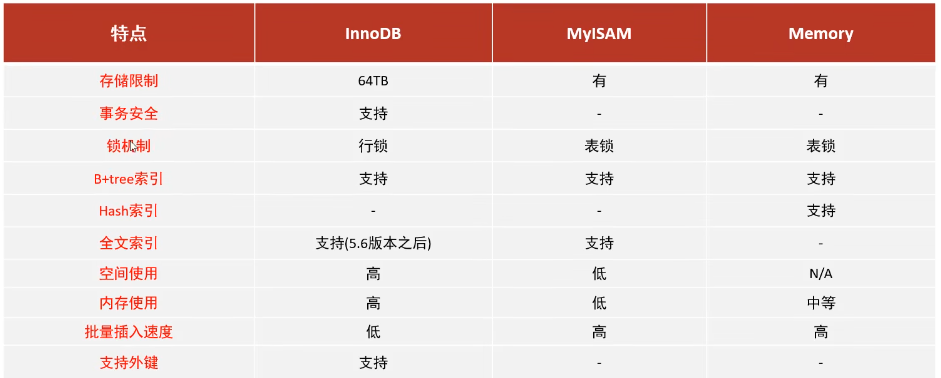
7.3 存储引擎特点
7.3.1 InnoDB
兼顾高可靠性和高性能的通用存储引擎,在mysql5.5之后,作为默认存储引擎。
- DML操作遵循ACID模型,支持事务。
- 行级锁,提高并发事务访问。
- 支持外键FOREIGN KEY约束,保证数据的完整性和正确性;
文件:
- xxx.ibd:xxx代表的是表名,innoDB引擎的每张表都会对应这样的一个表空间文件,存储该表的表结构(frm,sdi),数据和索引。
- 参数:innodb_file_per_table指定是否每张表都对应一个表文件。
逻辑存储结构
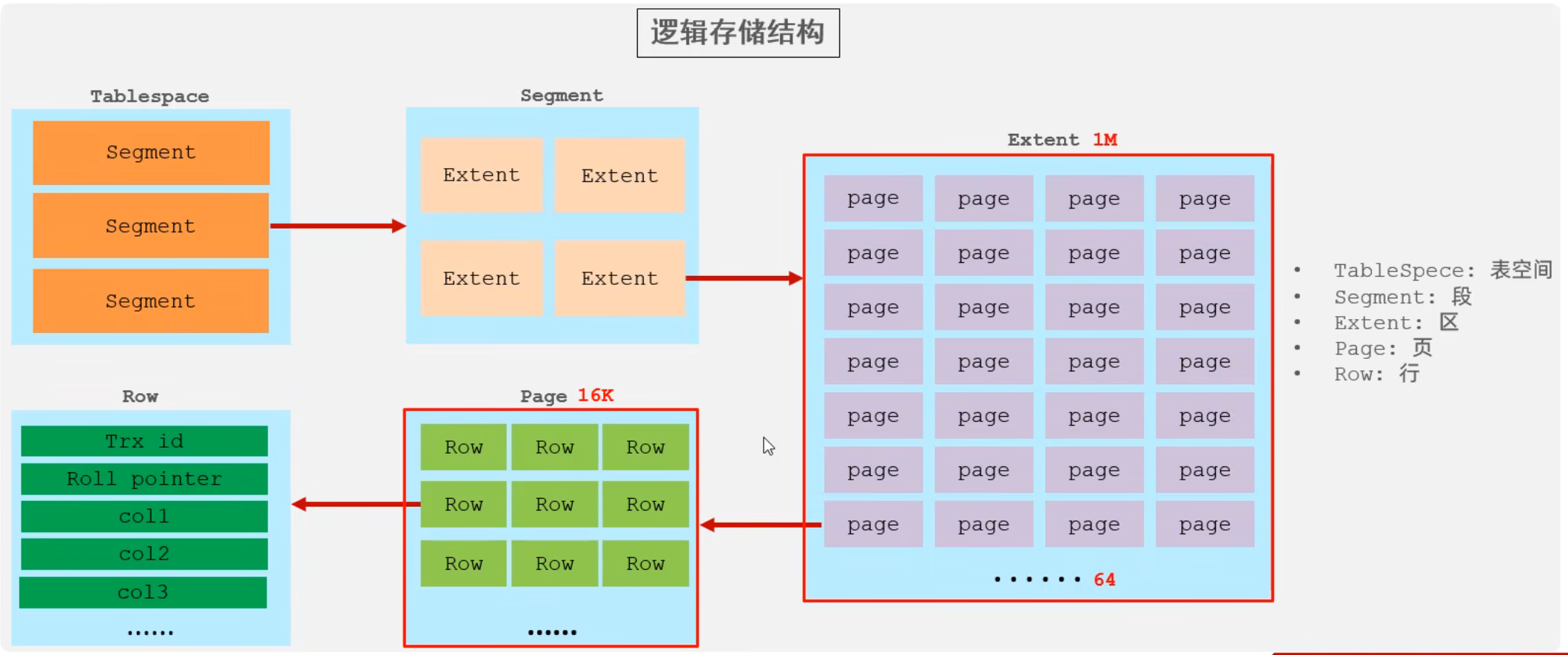
7.3.2 MyISAM
早期的默认存储引擎。
- 不支持事务,不支持外键
- 支持表锁,不支持行锁
- 访问速度快
文件
- xxx.sdi:存储表结构信息
- xxx.MYD:存储数据
- xxx.MYI:存储索引
7.3.3 Memory
存储在内存中,只能作为临时表或缓存使用
- 内存存放,访问速度快
- hash索引(默认)
文件
- xxx.sdi:存储表结构信息
7.4 存储引擎选择
- InnoDB:是Mysql的默认存储引擎,支持事务、外键。如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作,那么InnoDB存储引擎是比较合适的选择。
- MyISAM: 如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常合适的。
- MEMORY:将所有数据保存在内存中,访问速度快,通常用于临时表及缓存。MEMORY的缺陷就是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性。
8 索引
8.1 索引概述
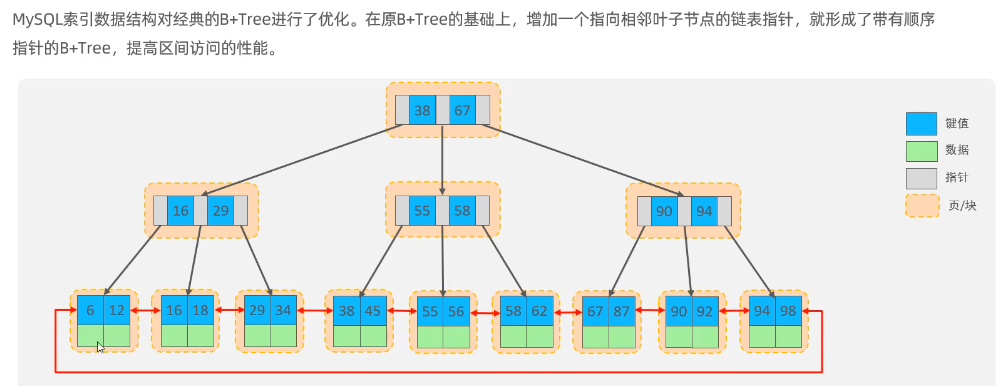
索引(index)是帮助mysql高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特性查找算法的数据结构,这些数据结构以某种方式指向数据,帮助快速查找数据。

8.2 索引结构
索引结构
因存储引擎不同而所有区别

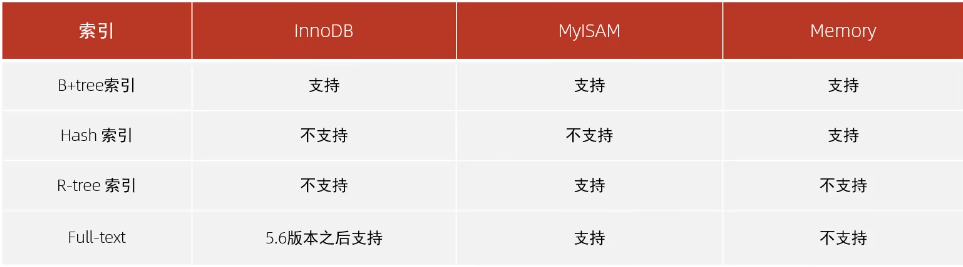
B+树
Hash
- 只能由于对等比较,不支持范围查询
- 无法利用索引完成排序
- 效率高,通常只需要一次检索,通常要优于B+树索引
为什么采用b+树
- 相对于二叉树,层级更少,搜索效率高
- 相对于b树,非叶子节点只存放索引,能够存放的索引更多,高度更低,效率更高
- 相对于hash,支持范围查询及排序操作
8.3 索引分类


聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引
- 如果不存在主键,将使用第一个唯一索引作为聚集索引
- 如果不存在主键,也没有合适的唯一索引,innodb会自动生成一个rowid作为隐藏的聚集索引
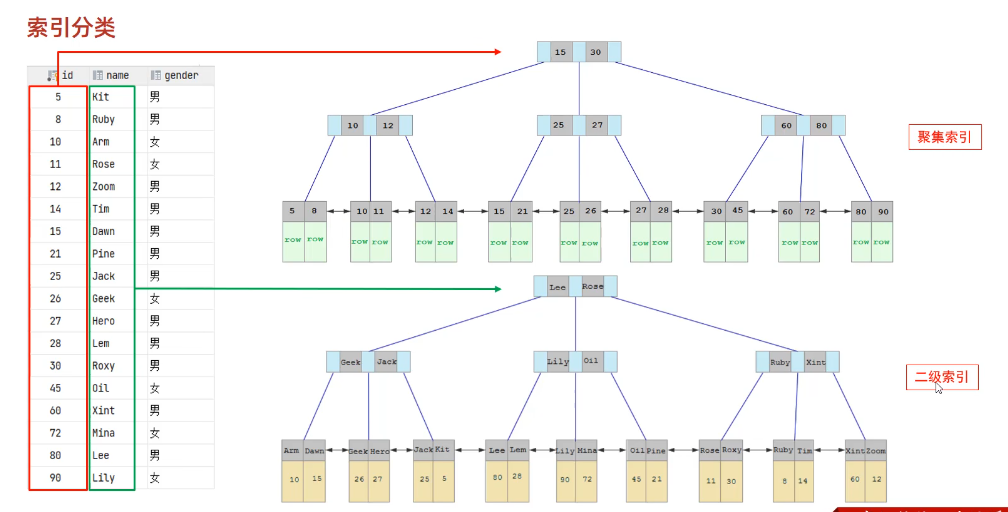
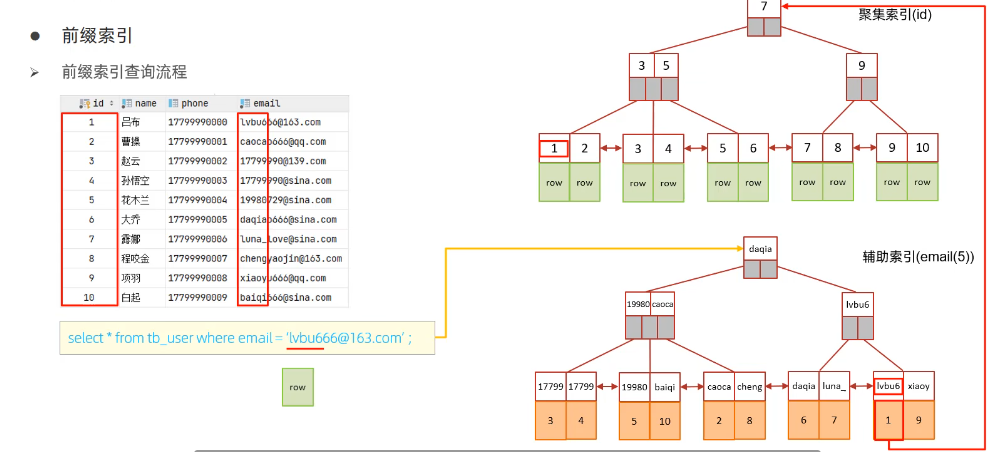
回表查询
先根据二级索引找到对应的主键值,再根据主键值去聚集索引中拿到对应的行数据。
8.4 索引语法
- 创建索引
1 | |
一个索引可以关联多个字段,如果只关联一个字段,则是单列索引,否则就是组合索引(联合索引)。
- 查看索引
1 | |
- 删除索引
1 | |
8.5 SQL性能分析
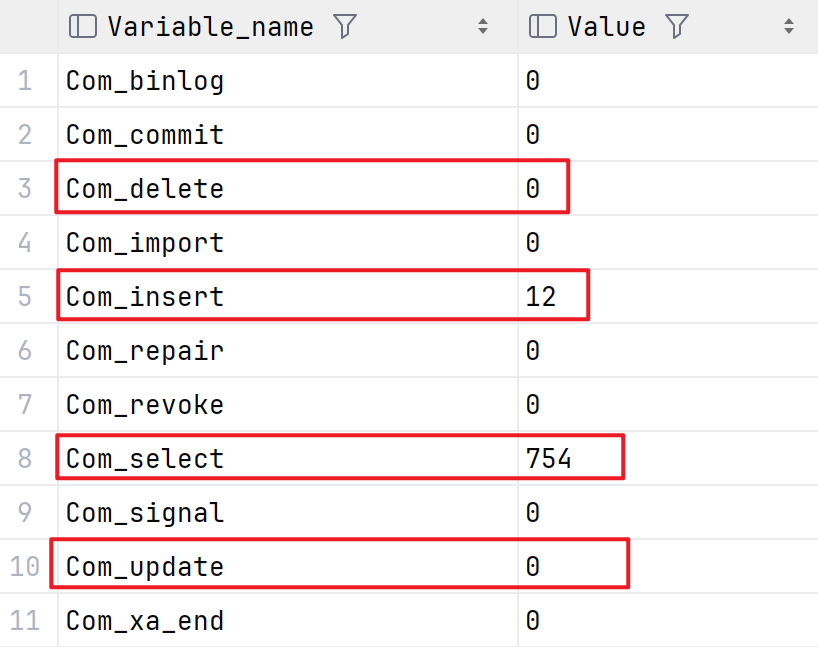
8.5.1 SQL执行频率
1 | |
8.5.2 慢查询日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time, 单位:秒,默认10s)的所有sql语句的日志。
mysql的慢查询日志默认没有开启,需要在mysql的配置文件(/etc/my.cnf)中配置如下信息

8.5.3 profile详情
show profiles能够在做sql优化时帮助我们了解时间耗费情况。通过have_profiling参数,能够查看当前数据库是否支持profile操作
1 | |
默认profiling是关闭的,可以通过set语句在session/global下开启profiling
1 | |
8.5.4 explain执行计划
explain或者desc命令获取mysql如何执行select语句的信息,包括在select语句执行过程中表如何连接和连接的顺序。
1 | |
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | account | null | ALL | null | null | null | null | 2 | 50 | Using where |
- id:select查询的序列号,表示查询中执行select子句或者是操作表的顺序(id相同,执行顺序从上到下,id不同,值越大,越先执行)。
- select_type:表示查询类型,常见的取值有simple(简单表,不使用表连接或者子查询)、primary(主查询,外层的查询)、union(union中的第二个或者后面的查询语句)、subquery(子查询)等。
- type:表示连接类型,性能由好到差的连接类型为NULL(不涉及表)、system(系统表)、const(唯一索引)、eq_ref、ref(非唯一性索引)、range、index(用了索引,但是仍然对整棵树进行扫描)、all(全表扫描)。
- possible_keys:显示可能应用在这张表上的索引。
- key:实际用到的索引
- key_len:使用到的索引的字节数,该值为索引字段的最大可能长度。
- rows:mysql认为必须要执行查询的行数,是一个估计值
- filtered:结果的行数占需读取行数的百分比
8.6 索引使用
- 最左前缀法则
如果索引了多列,要遵守最左前缀法则,即查询从索引的最左列开始,并且不跳过索引中的列。如果不包含最左边的列,索引全部失效;如果跳过了部分列,索引会部分失效(后面的字段的索引失效)。
- 范围查询
联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效。
1 | |
对于上面的语句,status索引失效。
规避方式就是在条件允许的情况下,尽量采用>=,<=。
- 索引列运算
不要在索引列上进行运算操作,否则索引会失效。
- 字符串类型加引号
不加引号,索引会失效
- 模糊查询
如果仅仅是尾部模糊匹配,索引不会失效,如果是头部模糊匹配,索引失效。
- or连接的条件
用or分开的条件,如果一个有索引,一个没有索引,那么涉及的索引都不会生效。
规避方式就是对涉及到的列都建立索引。
- 数据分布影响
如果mysql评估使用此索引比全表扫描还慢,就不使用索引。
- sql提示
在sql语句中加入一些人为的提示来达到优化操作的目的。

use index是一个建议,force index是强制。
- 覆盖索引
尽量使用覆盖索引(查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到),减少select*
extra信息:

- 前缀索引
当字段类型为字符串时,有时候索引很长,导致大量的磁盘io,影响查询效率。此时可以只将字符串的一部分前缀建立索引,提高索引效率。
1 | |
根据索引的选择性来决定前缀长度,选择性是指不重复的索引值和数据表的记录总数的比值。
计算选择性
1 | |
- 单列索引和联合索引
如果存在多个查询条件,建议建立联合索引。如果覆盖索引,不需要回表查询。
8.7 索引设计原则

9 SQL优化
9.1 插入数据
- 批量插入
采用批量插入优化插入多条数据操作,不建议超过1000条以上的数据。对于几万条数据,可以分为多条插入批量操作。
- 手动提交事务
- 主键顺序插入
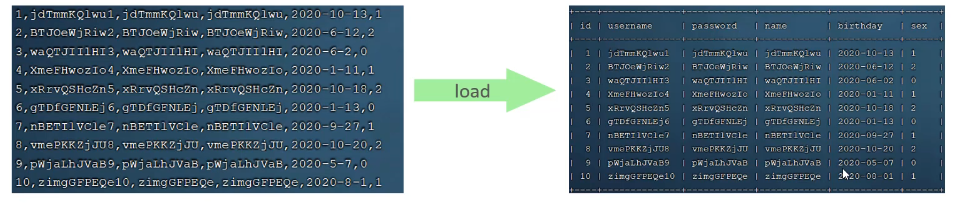
- 大批量插入数据
使用insert插入性能较低,可以使用load指令进行插入
1 | |
9.2 主键优化
- 数据组织方式
在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table,IOT)。
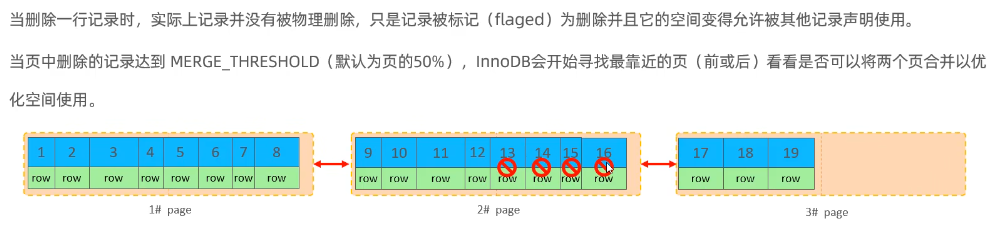
- 页分裂
页可以为空,也可以填充一半,也可以填充100%,每个页包含了2-N行数据,根据主键排列。
- 页合并
- 主键顺序插入

对于顺序插入,当一页满了之后,直接将新的行数据插入到新分配的页内即可,不会发生页分裂情况。
- 主键乱序插入
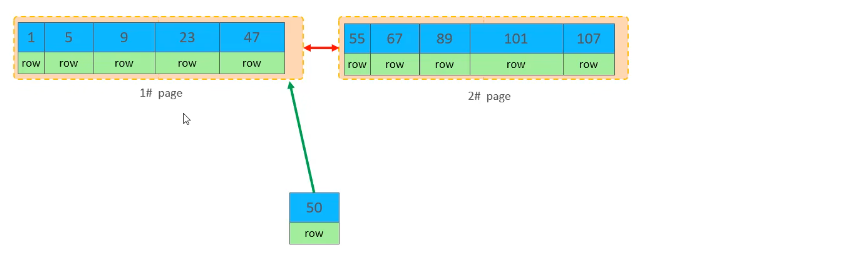


对于主键乱序插入,当新的行数据来了之后,需要根据顺序插入,此时前面的页如果满了,就会发生页分裂,将页一半的数据复制到新页中,然后插入数据,再调整链表指针。
主键设计原则
尽量降低主键长度
因为对于二级索引中存放的数据,就是主键,主键如果过长,会导致二级索引占用的空间变大。
插入数据时,尽量选择顺序插入,选择使用AUTO_INCREMENT自增主键。
尽量不要使用UUID做主键或者是其他自然主键,如身份证号。
避免对主键的修改
9.3 order by优化


9.4 group by优化
- 分组操作可以通过索引来优化
- 需要满足最左前缀法则
9.5 limit优化
对于limit,大数据量的时候,越往后的页,花费时间越长。因此此时mysql需要排序前面的数据,最后只返回最后的一页数据。
优化思路:通过创建覆盖索引加子查询的方式进行优化
1 | |
9.6 count优化

优化思路:自己计数(通过redis等)。
count的几种用法:count是一个聚合函数,对于返回的结果集,一行行地判断,如果不是null,累计值就+1。
count(*)

count(主键)

count(字段)

count(1)

按照效率排序
count(字段)<count(主键)<count(1)约等于count(*)。主要考虑是否取值,是否判断等因素。
9.7 update优化
InnoDB的行锁是针对索引加的锁,不是针对记录的,并且该索引不能失效,否则就会从行锁升级为表锁,导致并发性能降低。
10 视图
视图(view)是一种虚拟存在的表。视图中的数据并不在数据库中实际存在,行和列的数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成的。
- 创建
1 | |
- 查询
1 | |
- 修改
1 | |
- 删除
1 | |
- 检查选项
- 使用with check option创建视图时,mysql会检查正在更改的行,以使其符合视图定义。mysql允许基于另一个视图创建视图,它还会检查依赖视图中的规则以保证一致性。cascaded和local指明了检查的范围。默认为cascaded。
- cascaded:会级联检查每个依赖的视图的条件是否满足。
- local:会级联检查依赖视图的条件是否满足,如果依赖的视图没有设置检查选项,则不检查。
- 视图的更新
只有视图中的行于基表中的行存在一对一的关系时,视图才可以更新,如果视图包含一下任何一项,视图不可更新:

- 作用
- 简单:简化对数据的理解,简化操作。某些复杂查询可以被定义为视图,从而简化后续的查询。
- 安全:数据库可以授权,但是不能授权到特定行和特定列上,通过视图,用户只能查询和修改他们所能见到的数据
- 数据独立:屏蔽真实表结构带来的变化
11 存储过程
存储过程是事先经过编译并存储在数据库中的一段sql语句的集合,调用存储过程可以简化开发人员的工作,减少数据库和应用服务器之间的数据传输,可以提高数据处理效率。
思想上,存储过程就是数据库sql语言层面的代码封装与重用。
- 封装,复用
- 可以接受参数,可以返回数据
- 减少网络交互,效率提升
11.1 基本语法
- 创建
1 | |
- 调用
1 | |
- 查看
1 | |
- 删除
1 | |
11.2 变量
11.2.1 系统变量
mysql服务器提供,不是用户定义的,属于服务器层面,分为
- 全局变量(GLOBAL):针对所有会话有效。
- 会话变量(SESSION):针对当前会话有效。
查看系统变量
1 | |
设置系统变量
1 | |
mysql服务器重启之后,全局变量会重置。如果想永久生效,需要修改配置文件。
11.2.2 用户定义变量
用户根据业务需求自己定义的变量,不用提前声明,在用的时候直接用”@变量名“使用就可以,其作用域为当前连接。
赋值
1 | |
使用
1 | |
注意
用户定义变量不用提前声明,如果使用的时候还没有赋值,也不会报错,只不过变量的值为null