设计基于锁的并发数据结构 并发设计的内涵 线程安全
多线程执行的操作无论异同,每个线程所见的数据结构都是自恰的;数据不会丢失或破坏,所有不变量终将成立,恶性条件竞争也不会出现。
真正的并发
保护的范围越小,需要的串行化操作就越少,并发程度就可能越高。
基于锁的并发数据结构 基于锁实现线程安全的栈容器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #include <mutex> #include <stack> #include <exception> #include <memory> struct empty_stack : std::exception {const char * what () const throw () template <typename T>class ThreadSafeStack {public :ThreadSafeStack () = default ;ThreadSafeStack (const ThreadSafeStack& other) {std::lock_guard<std::mutex> lk (other.mtx_) ;operator =(const ThreadSafeStack&) = delete ;void push (T new_value) std::lock_guard<std::mutex> lk (mtx_) ;push (std::move (new_value));void pop (T& value) std::lock_guard<std::mutex> lk (mtx_) ;if (data_.empty ()) throw empty_stack ();move (data_.top ());pop ();std::shared_ptr<T> pop () {std::lock_guard<std::mutex> lk (mtx_) ;if (data_.empty ()) throw empty_stack ();auto res = std::make_shared <T>(std::move (data_.top ());pop ();return res;bool empty () const {lk (mtx_);return data_.empty ();private :mutable std::mutex mtx_;
每个成员函数都在内部互斥m之上加锁,因此这保障了基本的线程安全。这种方式保证了任何时刻都仅有唯一线程访问数据。
在empty()和每个pop()重载之间,都潜藏着数据竞争的隐患。然而,pop()函数不仅可以加锁,其还可以明文判别内部的栈容器是否为空,所以这不属于恶性数据竞争。
这段代码有可能引起死锁,原因是我们在持锁期间执行用户代码:栈容器所含的数据中,有用户自定义的复制构造函数、移动构造函数、拷贝赋值操作符和移动赋值操作符,用户也有可能自行重载new操作符。假使栈容器要插入或移除数据,在操作过程中数据自身调用了上述函数,则可能再进一步调用栈容器的成员函数,因而需要获取锁,但相关的互斥却已被锁住,最后导致死锁。向栈容器添加/移除数据,却不涉及复制行为或内存分配,这是不切实际的空想。合理的解决方式是对栈容器的使用者提出要求,由他们负责保证避免以上死锁场景。
需要使用者保证,必须当对象构造完成之后,别的线程才能访问数据;只有当所有线程都停止访问,才可以销毁对象。
该实现仅容许一次只有一个线程访问数据。性能有限。
该栈容器并未提供任何等待/添加数据的操作,因此,假如栈容器满载数据而线程又等着添加数据,它就必须定期反复调用empty(),或通过调用pop()而捕获empty_stack异常,从而查验栈容器是否为空。万一真的出现这种情况,本例的栈容器实现就绝非最佳选择,因为等待的线程只有耗费宝贵的算力查验数据,或者栈容器使用者不得不另行编写代码,以在外部实现“等待-通知”的功能(如利用条件变量),令内部锁操作变得多余且浪费。
采用锁和条件变量实现线程安全的队列容器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 #include <queue> #include <mutex> #include <condition_variable> template <typename T>class threadsafe_queue private :mutable std::mutex mut;public :threadsafe_queue ()void push (T new_value) {std::lock_guard<std::mutex> lk (mut) ;push (std::move (new_value));notify_one (); void wait_and_pop (T& value) {std::unique_lock<std::mutex> lk (mut) ;wait (lk,[this ]{return !data_queue.empty ();});move (data_queue.front ());pop ();std::shared_ptr<T> wait_and_pop () {std::unique_lock<std::mutex> lk (mut) ;wait (lk,[this ]{return !data_queue.empty ();}); std::shared_ptr<T> res ( std::make_shared<T>(std::move(data_queue.front()))) pop ();return res;bool try_pop (T& value) {std::lock_guard<std::mutex> lk (mut) ;if (data_queue.empty ())return false ;move (data_queue.front ());pop ();return true ;std::shared_ptr<T> try_pop () {std::lock_guard<std::mutex> lk (mut) ;if (data_queue.empty ())return std::shared_ptr <T>(); std::shared_ptr<T> res ( std::make_shared<T>(std::move(data_queue.front()))) pop ();return res;bool empty () const {std::lock_guard<std::mutex> lk (mut) ;return data_queue.empty ();
假定在数据压入队列的过程中,有多个线程同时在等待,那么data_cond.notify_one()的调用只会唤醒其中一个。然而,若该觉醒的线程在执行wait_and_pop()时抛出异常(譬如新指针std::shared_ptr<>在构建时就有可能产生异常④),就不会有任何其他线程被唤醒。
如果我们不能接受这种行为方式,则将data_cond.notify_one()改为data_cond.notify_all()。这样就会唤醒全体线程,但要大大增加开销:它们绝大多数还是会发现队列依然为空,只好重新休眠。
第二种处理方式是,倘若有异常抛出,则在wait_and_pop()中再次调用notify_one(),从而再唤醒另一线程,让它去获取存储的值。
第三种处理方式是,将std::shared_ptr<>的初始化语句移动到push()的调用处,令队列容器改为存储std::shared_ptr<>,而不再直接存储数据的值。从内部std::queue<>复制std::shared_ptr<>实例的操作不会抛出异常,所以wait_and_pop()也是异常安全的。
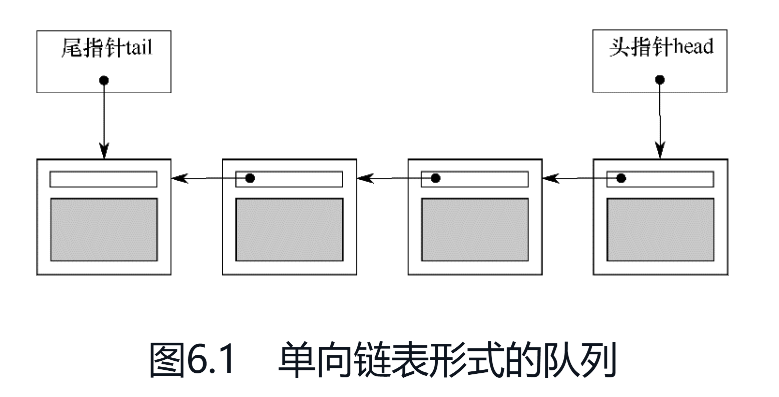
采用精细粒度的锁和条件变量实现线程安全的队列容器 用单向链表充当队列的数据结构。队列含有一个“头指针head”,它指向头节点,每个节点再依次指向后继节点。队列弹出数据的方法是更改head指针:将指向目标改为其后继节点,并返回原来的第一项数据。
新数据从队列末端加入,其实现方式是,队列另外维护一个“尾指针tail”,指向尾节点。假如有新节点加入,则将尾节点的next指针指向新节点,并更新tail指针,令其指向新节点。如果队列为空,则将head指针和tail指针都设置为NULL。
单线程版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <iostream> #include <memory> template <typename T>class Queue {public :queue () : tail (nullptr )queue (const queue& other) = delete ;operator =(const queue& other) = delete ;std::shared_ptr<T> try_pop () {if (!head) {return std::shared_ptr <T>();const res = std::make_shared (std::move (head->data));const auto old_head = std::move (head);move (old_head->next);if (!head) {nullptr ;return res;void push (T new_value) std::unique_ptr<node> p (new node(std::move(new_value))) ;const new_tail = p.get ();if (tail) {move (p);else {move (p);private :struct node {node (T data_):data (std::move (data_))
多线程下存在的问题:
push可以同时改动head指针和tail指针,所以该函数需要将两个互斥锁住。
push和try_pop有可能并发访问同一个节点的next指针:当队列仅含有一个节点的时候,即head==tail。这会导致锁定同一个互斥。
通过分离数据实现并发
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include <memory> #include <mutex> template <typename T>class threadsafe_queue private :struct node node* get_tail () {std::lock_guard<std::mutex> tail_lock (tail_mutex) ;return tail;std::unique_ptr<node> pop_head () {std::lock_guard<std::mutex> head_lock (head_mutex) ; if (head.get ()==get_tail ())return nullptr ;move (head);move (old_head->next);return old_head;public :threadsafe_queue ():head (new node),tail (head.get ())threadsafe_queue (const threadsafe_queue& other)=delete ;operator =(const threadsafe_queue& other)=delete ;std::shared_ptr<T> try_pop () {pop_head ();return old_head?old_head->data:std::shared_ptr <T>();void push (T new_value) {std::shared_ptr<T> new_data ( std::make_shared<T>(std::move(new_value))) std::unique_ptr<node> p (new node) ;const new_tail=p.get ();std::lock_guard<std::mutex> tail_lock (tail_mutex) ;move (p);
对于push而言,对tail指针的全部访问都需要加锁
对于try_pop而言,需要对head指针加锁,此外,还需要在内部访问tail指针一次,所以需要在对应的互斥上加锁。
在try_pop中,对tail的访问加锁是必要的保护。如果不加锁,try_pop和push可能会由不同的线程调用,导致对tail的访问出现竞争行为。
get_tail的调用在head_mutex保护范围中,这很重要。反之,先对tail加锁,获取到tail指针,再对head加锁,但此时可能无法顺利加锁,此时别的线程可能获取到锁进行try_pop,等到当前线程对head加锁的时候,head和tail都可能发生了改变,所以之前返回的tail指针可能不在是尾指针,甚至已经不是队列中的节点了。
并发性分析
push在没有持锁的状态下,为新节点和新数据完成了内存分配。
try_pop只在互斥tail_mutex上短暂持锁,因此try_pop和push几乎可以并发执行。
队列节点通过智能指针的析构函数删除,在head_mutex的保护范围以外执行,如此可以提高try_pop的并发度,因为删除节点、返回数据之类耗时的操作在互斥外执行。
等待数据弹出
进一步实现wait_and_pop等功能。
接口设计:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 template <typename T>class threadsafe_queue private :struct node public :threadsafe_queue ():head (new node),tail (head.get ())threadsafe_queue (const threadsafe_queue& other)=delete ;operator =(const threadsafe_queue& other)=delete ;std::shared_ptr<T> try_pop () ;bool try_pop (T& value) std::shared_ptr<T> wait_and_pop () ;void wait_and_pop (T& value) void push (T new_value) bool empty ()
向队列中压入新节点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 template <typename T>void threadsafe_queue<T>::push (T new_value)std::shared_ptr<T> new_data ( std::make_shared<T>(std::move(new_value))) std::unique_ptr<node> p (new node) ;std::lock_guard<std::mutex> tail_lock (tail_mutex) ;const new_tail=p.get ();move (p);notify_one ();
wait_and_pop实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 template <typename T>class threadsafe_queue private :node* get_tail () {std::lock_guard<std::mutex> tail_lock (tail_mutex) ;return tail;std::unique_ptr<node> pop_head () {move (head);move (old_head->next);return old_head;std::unique_lock<std::mutex> wait_for_data () {std::unique_lock<std::mutex> head_lock (head_mutex) ;wait (head_lock,[&]{return head.get ()!=get_tail ();});return std::move (head_lock); std::unique_ptr<node> wait_pop_head () {std::unique_lock<std::mutex> head_lock (wait_for_data()) ; return pop_head ();std::unique_ptr<node> wait_pop_head (T& value) {std::unique_lock<std::mutex> head_lock (wait_for_data()) ; move (*head->data);return pop_head ();public :std::shared_ptr<T> wait_and_pop () {const old_head=wait_pop_head ();return old_head->data;void wait_and_pop (T& value) {const old_head=wait_pop_head (value);
try_pop和empty实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 template <typename T>class threadsafe_queue private :std::unique_ptr<node> try_pop_head () {std::lock_guard<std::mutex> head_lock (head_mutex) ;if (head.get ()==get_tail ())return std::unique_ptr <node>();return pop_head ();std::unique_ptr<node> try_pop_head (T& value) {std::lock_guard<std::mutex> head_lock (head_mutex) ;if (head.get ()==get_tail ())return std::unique_ptr <node>();move (*head->data);return pop_head ();public :std::shared_ptr<T> try_pop () {try_pop_head ();return old_head?old_head->data:std::shared_ptr <T>();bool try_pop (T& value) {const old_head=try_pop_head (value);return old_head;bool empty () {std::lock_guard<std::mutex> head_lock (head_mutex) ;return (head.get ()==get_tail ());
完整代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 #include <memory> #include <iostream> #include <mutex> #include <condition_variable> #include <thread> template <typename T>class threadsafe_queue private :struct node public :threadsafe_queue ():head (new node),tail (head.get ())threadsafe_queue (const threadsafe_queue& other)=delete ;operator =(const threadsafe_queue& other)=delete ;std::shared_ptr<T> try_pop () {auto old_head = try_pop_head (); return old_head ? old_head->data : std::shared_ptr <T>();bool try_pop (T& value) auto old_head = try_pop_head (value);return old_head.get () != nullptr ;std::shared_ptr<T> wait_and_pop () {auto old_head = wait_pop_head ();return old_head ? old_head->data : std::shared_ptr <T>();void wait_and_pop (T& value) auto old_head = wait_pop_head (value);void push (T new_value) auto new_data = std::make_shared <T>(std::move (new_value));auto p = std::make_unique <node>();std::lock_guard<std::mutex> lk (tail_mutex) ;auto new_tail = p.get ();move (p);notify_one ();bool empty () std::lock_guard<std::mutex> lk (head_mutex) ;return head.get () == get_tail ();private :node* get_tail () {std::lock_guard<std::mutex> lk (tail_mutex) ;return tail;std::unique_ptr<node> pop_head () {auto old_head = std::move (head);move (old_head->next);return old_head; std::unique_lock<std::mutex> wait_for_data () {std::unique_lock<std::mutex> lk (head_mutex) ;wait (lk, [this ]{return head.get () != get_tail ();return std::move (lk);std::unique_ptr<node> wait_pop_head () {auto lk = wait_for_data ();return pop_head ();std::unique_ptr<node> wait_pop_head (T& value) {auto lk = wait_for_data ();move (*head->data);return pop_head (); std::unique_ptr<node> try_pop_head () {std::lock_guard<std::mutex> lk (head_mutex) ;if (head.get () == get_tail ()) {return std::unique_ptr <node>();return pop_head ();std::unique_ptr<node> try_pop_head (T& value) {std::lock_guard<std::mutex> lk (head_mutex) ;if (head.get () == get_tail ()) {return std::unique_ptr <node>();move (*head->data);return pop_head ();
附上一个简单的测试代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 #include <iostream> #include <vector> #include <thread> #include <atomic> #include <mutex> #include <cassert> #include <chrono> void single_thread_test () int > queue;assert (queue.empty ());push (42 );assert (!queue.empty ());int val;bool success = queue.try_pop (val);assert (success);assert (val == 42 );assert (queue.empty ());std::thread consumer ([&]{ int popped_val; queue.wait_and_pop(popped_val); assert(popped_val == 100 ); }) sleep_for (std::chrono::milliseconds (10 ));push (100 );join ();assert (queue.empty ());"Single thread tests passed!\n" ;void multi_thread_test () int > queue;const int NUM_ITEMS = 10000 ;std::atomic<int > counter (0 ) ;for (int i = 0 ; i < 2 ; ++i) {emplace_back ([&] {for (int j = 0 ; j < NUM_ITEMS; ++j) {push (j);for (int i = 0 ; i < 2 ; ++i) {emplace_back ([&] {for (int j = 0 ; j < NUM_ITEMS; ++j) {int val;wait_and_pop (val);for (auto & t : threads) {join ();int expected = 2 * (NUM_ITEMS-1 )*NUM_ITEMS/2 ;assert (counter.load () == expected);"Multi-thread tests passed!\n" ;int main () single_thread_test ();multi_thread_test ();return 0 ;
这个队列是无限队列。只要存在空闲内存,即便已存入的数据没有被移除,各个线程还是能持续往队列添加新数据。与之对应的是有限队列,其最大长度在创建之际就已固定。一旦有限队列容量已满,再试图向其压入数据就会失败,或者发生阻塞,直到有数据弹出而产生容纳空间为止。
采用锁编写线程安全的查找表 查找表的使用方式不同于栈容器或队列容器。栈容器和队列容器的几乎每项操作都会进行改动,或增加元素,或删减元素,查找表却鲜有改动。
从并发的角度考虑,std::map<> 接口中的最大问题是迭代器。有一种思路是通过迭代器访问容器内部,即便有其他线程访问(并改动)容器数据,迭代器所提供的访问依然安全。这虽然可行,但颇为棘手。要令迭代器正确运行,我们就必须面对诸多问题,这些问题处理起来相当复杂,例如一个线程要删除某个元素,而它却正被迭代器引用。考虑到 std::map<> 严重依赖迭代器(标准库中的其他关联容器亦然),所以我们自己设计接口。
查找表基本接口:
增加配对的键/值对
根据给定的键改变关联的值。
移除某个键及其关联的值。
根据给定的键获取关联值(若该键存在)。
一些针对容器自身的整体操作也十分有用,如检查容器是否为空、以“快照”方式复制所有键或全体键/值对。
为了实现更高的并发度,我们不能简单地对标准库提供的容器进行一层封装,这样并发度不高。考虑关联容器的几种实现方式:
红黑树每次查找或改动都要从根节点开始访问,必须逐层加锁解锁,提升不大;有序数组因为无法预知查找的目标的位置,所以必须对整个数组加锁,效率更差。所以我们选择散列表。
假定散列表具有固定数量的桶,每个键都属于一个桶,键本身的值和散列函数决定键具体属于哪个桶。这让我们可以安全地为每个桶使用独立的锁,从而增加并发度。问题是,我们需要一个针对键的散列函数。我们可以使用C++标准库提供的函数模板 std::hash<>。该函数已经具备针对基础类型的特化版本,如 int 和 std::string ,用户也可以方便地对其他类型的键进行特化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 #include <memory> #include <mutex> #include <list> #include <map> #include <algorithm> #include <shared_mutex> template <typename Key, typename Value, typename Hash = std::hash<Key>>class threadsafe_lookup_table {private :class bucket_type {private :using bucket_value = std::pair<Key, Value>;using bucket_data = std::list<bucket_value>;using bucket_iterator = typename bucket_data::iterator;mutable std::shared_mutex mtx;bucket_iterator find_entry_for (const Key& key) const {return std::find_if (data.begin (), data.end (), [&key](const bucket_value& item){return item.first == key;public :Value value_for (const Key& key, const Value& default_value) const {std::shared_lock<std::shared_mutex> lk (mtx) ;const auto found_entry = find_entry_for (key);return found_entry == data.end () ? default_value : found_entry->second;void add_or_update_mapping (const Key& key, const Value& value) std::unique_lock<std::shared_mutex> lk (mtx) ;const auto found_entry = find_entry_for (key);if (found_entry == data.end ()) {push_back (bucket_value (key, value));else {void remove_mapping (const Key& key) std::unique_lock<std::shared_mutex> lk (mtx) ;const auto found_entry = find_entry_for (key);if (found_entry != data.end ()) {erase (found_entry);bucket_type& get_bucket (const Key& key) const {const auto bucket_idx = hasher (key) % buckets.size ();return *buckets[bucket_idx];public :using key_type = Key;using mapped_type = Value;using hash_type = Hash;threadsafe_lookup_table (unsigned num_buckets = 19 , const Hash& hasher_ = Hash ())buckets (num_buckets), hasher (hasher_) {for (unsigned i = 0 ; i < num_buckets; ++i) {reset (new bucket_type);threadsafe_lookup_table (const threadsafe_lookup_table&) = delete ;operator =(const threadsafe_lookup_table&) = delete ;Value value_for (const Key& key, const Value& default_value = Value()) const {return get_bucket (key).value_for (key, default_value);void add_or_update_mapping (const Key& key, const Value& value) get_bucket (key).add_or_update_mapping (key, value);void remove_mapping (const Key& key) get_bucket (key).remove_mapping (key);std::map<Key, Value> get_map () const {for (const auto & bucket : buckets) {push_back (std::unique_lock <std::shared_mutex>(bucket.mtx));for (const auto & bucket : buckets) {for (auto it = bucket.data.begin (); it != bucket.data.end (); ++it) {insert (*it);return res;
因为桶的数量是固定的,因此对buckets的访问无需加锁。对于每个桶的访问,都由共享锁妥善的处理进行了保护。
异常安全:
value_for不涉及改动,即使抛出异常,也不污染数据结构。
remove_mapping通过erase改动链表,该调用肯定不会抛出异常。
add_or_update_mapping如果执行add操作,进行push_back,该操作是异常安全的,即使抛出异常,也不会污染链表。如果执行update操作,进行赋值操作,该操作不是异常安全的,可能会使关联的值处于混合状态。可以将异常安全交给使用者处理。
采用多种锁编写线程安全的链表 前面提到在多线程情况下,我们需要避免支持迭代器。为了提供迭代功能,可以考虑用成员函数的形式来实现,例如for_each。但是可能会导致死锁,因为如果for_each的存在要有意义,则其必须在持有内部锁的时候运行用户代码,而且还必须向用户传递每一项数据,而且数据应该按值传递。我们只有要求使用者来确保其提供的用户代码不会试图获取锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 #include <memory> #include <mutex> template <typename T>class threadsafe_list {struct node {node () :next ()node (const T& value):data (std::make_shared <T>(value)),next ()public :threadsafe_list () = default ;threadsafe_list () {threadsafe_list (const node&) = delete ;operator =(const threadsafe_list&) = delete ;void push_front (const T& value) auto new_node = std::make_unique <node>(value);std::lock_guard<std::mutex> lk (head.mtx) ;move (head.next);move (new_node);template <typename Function>void for_each (Function f) auto cur_node = &head;std::unique_lock<std::mutex> lk (head.mtx) ;while (node* const next = cur_node->next.get ()) {std::unique_lock<std::mutex> next_lk (next->mtx) ;unlock ();f (*next->data);move (next_lk);template <typename Predicate>std::shared_ptr<T> find_first_if (Predicate p) {auto cur_node = &head;std::unique_lock<std::mutex> lk (head.mtx) ;while (node* const next = cur_node->next.get ()) {std::unique_lock<std::mutex> next_lk (next->mtx) ;unlock ();if (p (*next->data)) {return next->data;move (next_lk);return std::shared_ptr <T>();template <typename Predicate>void remove_if (Predicate p) auto cur_node = &head;std::unique_lock<std::mutex> lk (head.mtx) ;while (node* const next = cur_node->next.get ()) {std::unique_lock<std::mutex> next_lk (next->mtx) ;if (p (*next->data)) {auto old_next = std::move (cur_node->next);move (next->next);unlock ();else {unlock ();move (next_lk);
以上实现的核心思想是,按照链表中节点的前后顺序加锁,没有任何一个线程能够超越他人的处理节点,若一个线程需在某节点上耗费特别长的时间,那么其他线程在到达该节点时就不得不等待。