[OS]Three Easy Pieces Chapter 9
Scheduling: Proportional Share
在本章中,将研究一种不同类型的调度程序,即比例共享(proportional share)调度程序,有时也称为公平共享(fair-share)调度程序。比例共享调度器基于一个简单的概念:调度器可以不对周转时间或响应时间进行优化,而是设法保证每个作业都能获得一定比例的 CPU 时间。其基本思想非常简单:每隔一段时间举行一次抽签,决定下一个运行的进程;应该更频繁运行的进程应该有更多机会中签。
1 Basic Concept: Tickets Represent Your Share
抽签调度的基础是一个非常基本的概念:tickets,用来表示进程(或用户或其他)应获得的资源份额。一个进程拥有的 ticket 的百分比代表了它在相关系统资源中的份额。
抽签调度每隔一段时间进行一次抽签,随机抽一个ticket出来,然后调度拥有该ticket的进程运行。
2 Ticket Mechanisms
ticket currency
该机制允许用户根据需要给自己的任务分配货币,然后操作系统根据该用户所有的ticket以及子任务的货币计算出每个子任务的tickets。
比如,最开始A,B各自有100个tickets

ticket transfer
一个进程可以暂时将自己的tickets转给另外一个进程。该策略在CS模式下非常有用。
当客户需要服务器帮自己完成某些工作的时候,一并将自己的tickets转给服务器,服务器完成之后,将tickets再转回客户。
ticket inflation
在互相信任的环境中,进程可以通过增加或减少其ticket来适应其资源需求。
3 Implementation
抽签调度最大的优势就是其实现非常简单,只需要:
- 一个设计良好的随机数生成器
- 一个维护所有进程的数据结构
- tickets总数

要做出调度决策,我们首先要从ticket总数中随机抽取一个数字(中奖者)。然后,我们只需遍历列表,用一个简单的计数器帮助我们找到中奖者。代码会遍历进程列表,将每个进程的tickets添加到计数器中,直到计数器超过中奖者为止。一旦出现这种情况,当前列表中的进程就是中奖者。
4 How To Assign Tickets
一个方法是认为用户知道如何分配。但这其实并没有解决实际的问题。
5 Stride Scheduling
该策略是用一个很大的数除以每个进程的ticket,得到每个进程的stride,并用一个计数器来记录每个进程的执行进度(pass)。每次执行一个进程,将其pass增加stride。每次调度都会选取pass值最小的那个进程来执行。
抽签调度的优势
相较于stride scheduling,抽签调度的优势是没有全局状态,即没有pass。当有一个新的进程添加的时候,对于stride scheduling,我们不能将其pass简单的设置为0,否则该新进程会主宰系统。而对于抽签调度,我们无需考虑这个问题,只要设置好对应的tickets即可。
6 The Linux Completely Fair Scheduler(CFS)
Linux的CFS调度器实现了公平共享调度,而且是以高效和可扩展的方式实现的。
Basic Operation
大多数调度程序都基于固定时间片的概念,而 CFS 的运行方式则有些不同。它的目标很简单:在所有竞争进程之间公平分配 CPU。它通过一种简单的基于计数的技术来实现这一目标,这种技术被称为虚拟运行时间(vruntime)。
每个进程运行时都会累积 vruntime。在最基本的情况下,每个进程的 vruntime 都以相同的速度增长,与物理(实际)时间成比例。在进行调度决策时,CFS 会选择 vruntime 最低的进程作为下一个运行进程。
调度程序如何知道何时停止当前正在运行的进程,并运行下一个进程?这里的矛盾很明显:如果 CFS 切换过于频繁,公平性会提高,因为 CFS 将确保每个进程即使在微小的时间窗口内也能获得其 CPU 份额,但代价是性能下降(上下文切换过多);如果 CFS 切换频率较低,性能会提高(上下文切换减少),但代价是近期公平性下降。
CFS 通过各种控制参数来处理这种矛盾。
首先是 sched_latency。CFS 使用该值来确定一个进程在考虑切换前应运行多长时间。典型的调度延迟值为 48(毫秒);CFS 将此值除以 CPU 上运行的进程数(n)来确定进程的时间片,从而确保在这段时间内,CFS 完全公平。
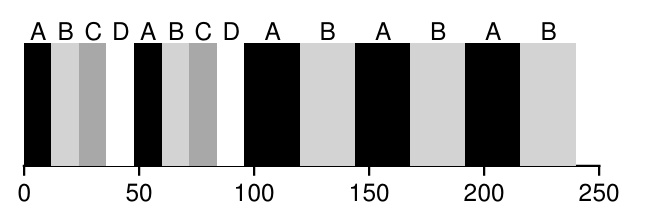
上述是一个例子,最开始有四个进程ABCD,因此最开始的时间片是48/4 = 12ms,之后CD运行完毕,只剩两个进程AB,每个进程的时间片是48/2 = 12ms。
但是,当进程过多的时候,会导致每个进程的时间片过多,导致频繁的上下文切换。为了解决这个问题,CFS用另外一个参数来控制,min_granularity ,一般设置为6ms。CFS永远不会将时间片的值设置的比 min_granularity 小,保证上下文切换不会太过频繁。
Weighting(Niceness)
CFS(完全公平调度器)还允许对进程优先级进行控制,让用户或管理员可以为某些进程分配更多的CPU资源。这种控制不是通过ticket,而是通过UNIX经典的“nice”机制来实现的。进程的nice参数范围在 -20 到 +19 之间,默认值是 0。正的nice值意味着较低的优先级,负的nice值则表示较高的优先级。
CFS将nice值映射到weight,并根据一下公式来计算每个进程的时间片。

$$
time_slice_k = \frac{weight_k}{\Sigma_{i = 0}^{n - 1}weight_k} · sched_latency
$$
为了配合时间片计算,vruntime的计算公式也要做出相应的修改,其中$weight_0$是默认权重,为1024,$runtime_i$是某个进程的实际运行时间。
$$
vruntime_i=vruntime_i + \frac{weight_0}{weight_i} · runtime_i
$$
使用权重表的设计的聪明之处在于,当进程之间的nice值差异保持不变时,CPU分配比例也能保持不变。换句话说,即使两个进程的nice值发生变化,只要它们之间的差值相同,它们的CPU分配比例不会变。
举个例子:假设最初进程A的nice值为0,进程B的nice值为5。后来我们将A的nice值调整为5,B的nice值调整为10。虽然两个进程的nice值都变了,但由于它们的nice差值仍然是5,CFS会以与之前相同的方式调度它们,保持相同的CPU分配比例。
Using Red-Black Trees
CFS使用红黑树来维护所有runnable的进程(其他状态的进程由其他数据结构来维护)。这可以保证每次选取最小vruntime的进程的时间复杂度为$O(logn)$。
为什么不适用小顶堆来维护?
关于这个问题,可以参考linux kernel - Reason why CFS scheduler using red black tree? - Stack Overflow
Dealing With I/O And Sleeping Process
在选择下一个运行的最低 vruntime 时会遇到一个问题,那就是作业已经休眠了很长时间。设想有两个进程,A 和 B,其中一个进程(A)持续运行,而另一个进程(B)已经休眠了很长时间(比如 10 秒)。当 B 唤醒时,它的 vruntime 将比 A 晚 10 秒,因此,B 将在接下来的 10 秒内独占 CPU,同时赶上 A,这实际上会饿死 A。
实际上,CFS 会将该作业的 vruntime 设置为在树中找到的最小值。通过这种方式,CFS 避免了 “饥饿”,但也付出了代价:作业如果经常处于短时间睡眠状态,就无法获得公平的 CPU 资源。