[MIT 6.S081]Lab1 Xv6 and Unix utilities
1 通过gdb调试
参考链接
- Homework: running and debugging xv6 (archive.org)
- MIT 6.S081 xv6调试不完全指北 - KatyuMarisa - 博客园 (cnblogs.com)
- GDB-cheat-sheet.pdf (gabriellesc.github.io)
2 sleep(easy)

结果如下:

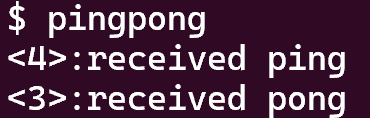
3 pingpong(easy)

本题考查的是管道通信相关内容的理解。
If no data is available, a read on a pipe waits for either data to be written or for all file descriptors referring to the write end to be closed; in the latter case, read will return 1, just as if the end of a data file had been reached.
xv6书中指出,read会一直阻塞直到有数据被写入管道或者所有指向管道写端的文件描述符都被关闭。
一种简单的实现是创建两个管道,一个管道的流向为父进程到子进程,另外一个的流向为子进程到父进程。
另外一种实现只需要创建一个管道,但是由于父子进程读写的都是同一个管道,需要通过wait来同步父子进程读写的顺序,防止出现死锁的情况。代码如下,注意55行的 wait((int*)0),父进程一定要等待子进程退出后,才可以从管道中读取数据,否则可能会出现父进程自写自读的情况,导致子进程阻塞在21行处。
1 | |
结果如下

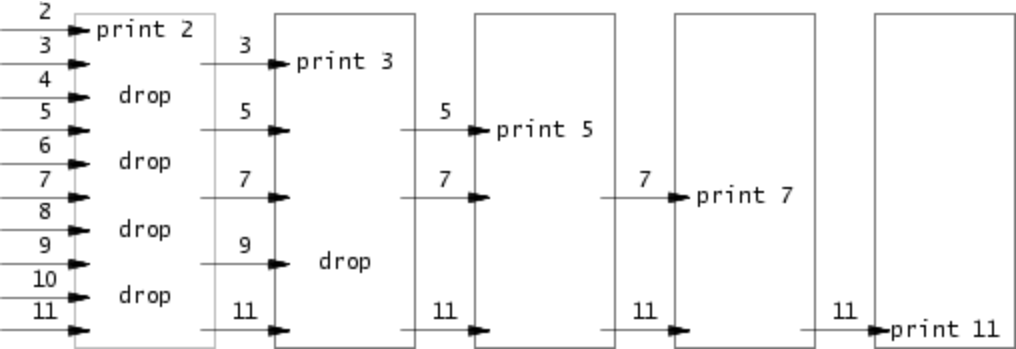
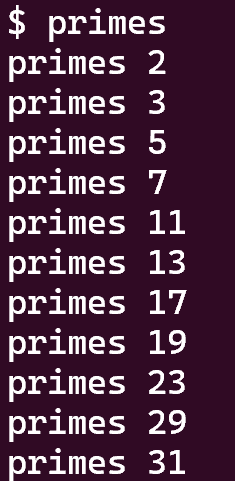
4 primes (moderate)/(hard)

这道题目考察的是利用 fork 进行多进程编程。
重点是理解下面的图和伪代码。本题用到了一种编程思想(Bell Labs and CSP Threads (swtch.com)),通过未缓冲的命名的通道来同时进行通信和同步。因为管道未缓冲,所以可以通过读写阻塞来进行同步。

1 | |
结果如下:

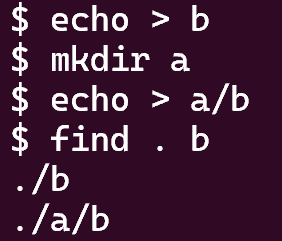
5 find (moderate)

这道题目考察的是对xv6文件系统的理解,比较简单,参考 user/ls.c 即可。
1 | |
结果如下:

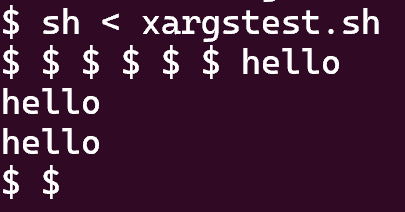
6 xargs (moderate)

这道题目的难点主要在于对c语言数组的处理。
大致思路如下:
1.首先将xargs的参数拷贝到数组的前段。
2.然后从标准输入读取一行的内容作为额外参数拼接到数组后面,这里我们一行的内容只作为一个参数处理。
3.fork一个子进程出来调用exec执行命令
4.父进程调用wait等待子进程执行完毕,之后跳转到2继续执行。
1 | |
结果如下:

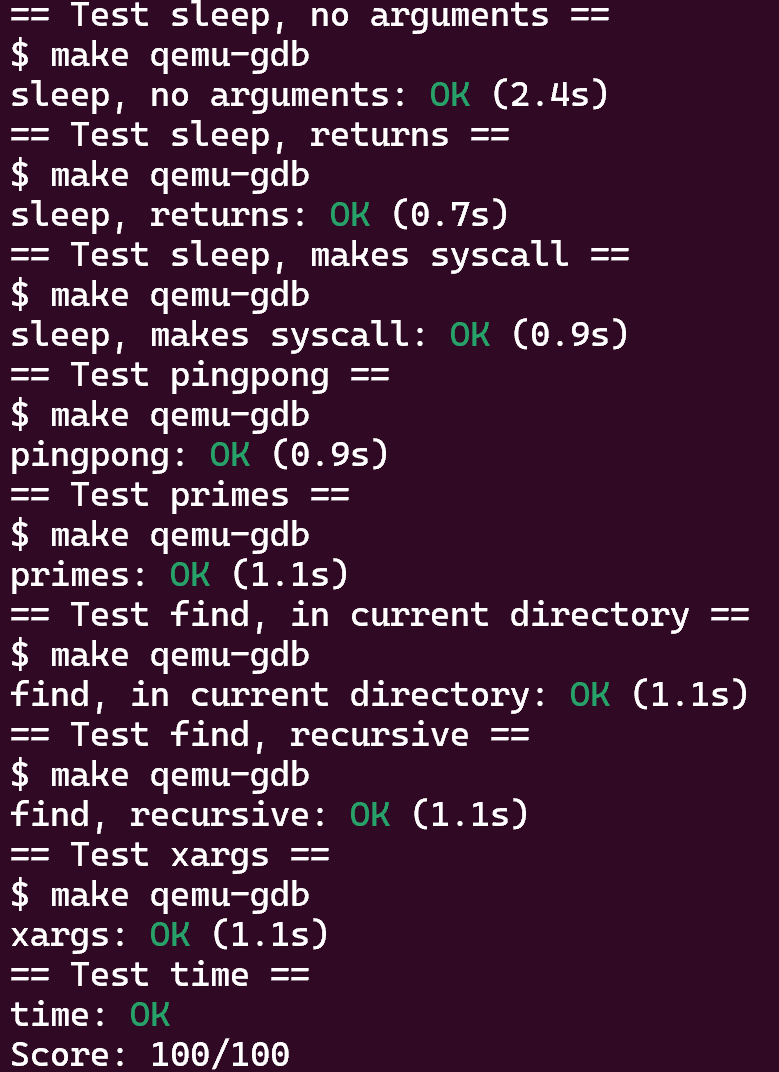
7 测试结果
8 uptime(easy)
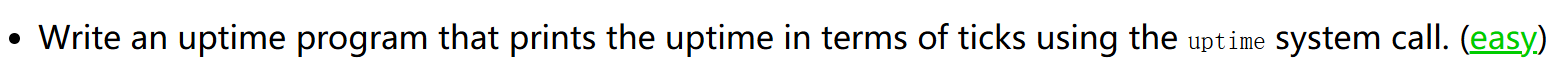
1 | |
9 improve find(easy)
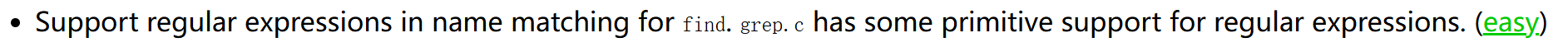
这道题目直接参考grep.c,把其中正则表达式匹配的代码拿过来,修改find中判断匹配的条件即可。
1 | |
10 improve shell(easy/moderate)
